Java fork/join 详解
概述
Java 7 引入了 fork/join 框架,fork 是分叉,join 是合并,其实这是分治算法的体现。分叉的意思是一个大的任务分解成若干小的任务(即所谓的 fork),再将这些小的任务提交给线程池并发执行,最后将每个小的任务的结果合并起来得到最终的结果(即所谓的 join)。
fork/join 框架内部使用 ForkJoinPool 线程池,该线程池中的工作线程为 ForkJoinWorkerThread。
fork/join
fork/join 的核心是 ForkJoinPool 线程池,我们需要将大的任务分解成小任务,这些小任务最终被池中的工作线程执行。每个工作线程都有自己的工作队列,可以认为这个队列是双端队列,用来存储待执行的任务。
工作线程优先从自己的队列中获取任务并执行,当自己的队列为空时,从其他队列的尾端 “窃取”(stealing) 任务执行,这样可以很好的均衡任务。
获取一个共享的 ForkJoinPool 线程池的方法如下:
ForkJoinPool commonPool = ForkJoinPool.commonPool();
fork/join Task
ForkJoinPool 线程池中的工作线程执行的 task 类型为 ForkJoinTask,task 一般分两种:
- RecursiveAction,这种类型针对没有返回值的任务。
- RecursiveTask<V>,该类型定义返回值的类型为 V。
不论哪种类型的 task,我们实现 compute 抽象方法即可。下一节我们将举例说明 RecursiveTask 的用法,假设有一个很大的数组,我们需要求这个数组的和,使用 fork 将数组分解成小的数组分别求和,最后使用 join 将这些结果合并为最终的结果。
RecursiveTask 实战
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class MySumTask extends RecursiveTask<Integer> {
private final Integer[] arr;
private static final int minSubTasks = 2;
public MySumTask(Integer[] arr) {
this.arr = arr;
}
@Override
protected Integer compute() {
System.out.println("compute called, arr is: " + Arrays.toString(this.arr));
if (this.arr.length <= minSubTasks) {
// 任务足够小的话,没必要 fork,直接执行任务即可
return process(this.arr);
}
MySumTask subTask1 = new MySumTask(Arrays.copyOfRange(arr, 0, arr.length / 2));
MySumTask subTask2 = new MySumTask(Arrays.copyOfRange(arr, arr.length / 2, arr.length));
// fork
ForkJoinTask.invokeAll(subTask1, subTask2);
// join
Integer subTask1Ret = subTask1.join();
Integer subTask2Ret = subTask2.join();
return subTask1Ret + subTask2Ret;
}
private Integer process(Integer[] arr) {
return Arrays.stream(arr).reduce(0, Integer::sum);
}
}
MySumTask 的核心就在于实现 compute 方法,当任务足够小的时候就没必要再分,上例中我们使用 minSubTasks 表示一个数组的长度小于等于 2 就没必要再分。实际场景中当然没必要将任务分的这么小,我们之所以使用 2,是为了方便后面的讲解。
仔细观察 compute 方法会发现,当数组的长度大于 minSubTasks 时,会将数组一分为二,创建两个新的 MySumTask 子任务,之后便是分别调用两个子任务的 join。最后将两个子任务的结果想加得到最终结果。
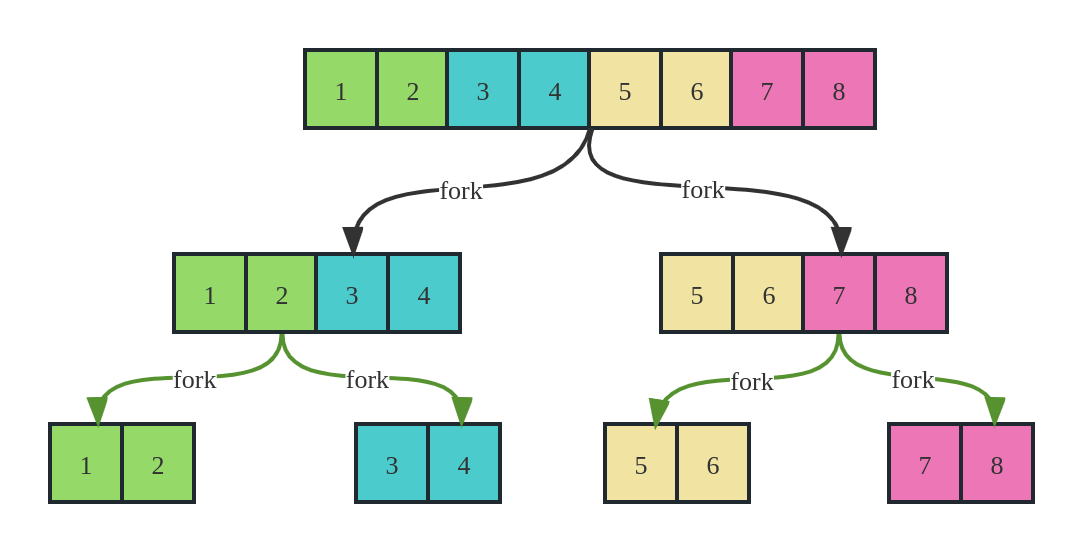
从代码中我们只看到将数组一分为二,难道数组只是被分为两个吗?当然不是,前面我们其实说到了数组会被一直切分,直到数组长度小于等于 minSubTasks。其实每个子任务也会调用到 compute,又可能产生新的子任务,是一个典型的递归过程。
下面我们来看怎么执行这个数组求和任务:
public static void main(String[] args) {
Integer[] arr = new Integer[] {1, 2, 3, 4, 5, 6, 7, 8};
MySumTask sumTask = new MySumTask(arr);
Integer result = ForkJoinPool.commonPool().invoke(sumTask);
System.out.println("sum result is: " + result);
}
任务的执行结果如下:
compute called, arr is: [1, 2, 3, 4, 5, 6, 7, 8]
compute called, arr is: [1, 2, 3, 4]
compute called, arr is: [5, 6, 7, 8]
compute called, arr is: [1, 2]
compute called, arr is: [5, 6]
compute called, arr is: [7, 8]
compute called, arr is: [3, 4]
sum result is: 36
任务分解的过程给大家配张图:
总结
使用 fork/join 框架提供的分治算法和并发处理可以加快大型任务的处理速度,但在使用过程中,我们需要遵循一些准则:
- 尽可能少地使用线程池,多数情况下,每个应用程序或系统使用一个线程池即可。
- 应该合理的切分子任务的数量,只有大任务才有必要使用 fork/join 线程池来处理,小任务使用花费的时间反而可能更多。
- ForkJoinTask 不应该用来执行阻塞任务,特别是使用
ForkJoinPool.commonPool()公共线程池的时候,如果有阻塞将会极大的影响其他任务的执行。
温馨提示:反馈需要登录


