Redis 常用数据结构
概述
简要介绍 Redis 中 5 种常用数据类型,以及他们各自的使用场景。
Strings
存储字符串,确切的说是存储字节序列。他的底层类型是 SDS(simple dynamic string),称为动态字符串。所能支持的最大字符串为 512 MB。SDS 记录了字符串长度,获取长度时间复杂度为 O(1),而 C 语言则需要遍历获取字符串长度,时间复杂度为 O(n)。
使用场景:
- 存储字符串;
- 存储对象,可以将对象序列化为 JSON 后存储;
- SETNX 可以用来实现分布式锁;
- 实现计数器:
INCR key
Lists
List 结构类似一个双向链表,两头都可以插入和删除,而且该结构还实现了阻塞队列的功能。
使用场景:
- Stack(栈) = LPUSH + LPOP
- Queue(队列)= LPUSH/RPOP 或者 RPUSH/LPOP
- Blocking MQ(阻塞队列)= LPUSH + BRPOP
- 安全阻塞队列 = LPUSH + BRPOPLPUSH + LREM
安全阻塞队列的实现原理是:利用 LPUSH 生产数据,BRPOPLPUSH 消费数据,同时将消费的数据备份到一个新的队列,最后如果消费成功利用 LREM 将备份队列的数据删除。
底层数据结构:
quicklist,quicklist 节点中每个节点中则包含一个 ziplist。
Sets
无序集合,和 Java 的 HashSet 很像。
使用场景:
- 记录唯一项,例如追踪某篇博客的独立ip;
- 关系运算,利用集合运算可以很容易实现两个人的共同好友;
底层数据结构:
如果 set 中存储都是用 64 bit 可以表示的带符号整形,且元素个数不超过指定个数(可配置,见下面的配置项,默认值是 512),内部使用的是 inset,intset 中存储的元素实际上存储在一个连续且排好序的数组中。如果不满足之前提到的条件则采用 hashtable 存储。
set-max-intset-entries 512
Hashes
使用场景:
- 可以用来存储对象,对象的属性和属性值正好作为 Hash 的键值对;
- 用 HINCRBY 实现一组计数器。
# 存储对象
HSET user:idxx name lucy
HSET user:idxx age 20
HSET user:idxx mobile 18536564236
#一组计数器
HINCRBY counters counter1 1
HINCRBY counters counter2 1
底层数据结构:
可能会使用两种数据结构,一种是 ziplist,当 ziplist 中元素的个数大于指定值或者任一元素的最大长度超过一定阈值时改用 hashtable 存储。redis 中默认情况下:
# 元素个数不超过 512 个
hash-max-ziplist-entries 512
# 每个元素的大小不超过 64 字节
hash-max-ziplist-value 64
注: ziplist 作为哈希的内部实现是因为 ziplist 结构更加紧凑,并使用连续内存存储元素(相对于 linklist 能够减少内存碎片),所以在节省内存方面比 hashtable 更加优秀,特别是在元素个数不多且元素的内容长度不大的情况下。但是随着 ziplist 中元素的增加,ziplist 为了保证他存储内容在内存中的连续性, 插入的复杂度是 O (N), 即每次插入都会重新进行 realloc,此时使用 hashtable 就更合适了。
为什么数据量大时不用 ziplist?
因为 ziplist 是一段连续的内存,插入的时间复杂化度为 O(N),而且每当插入新的元素需要 realloc 做内存扩展;而且如果超出 ziplist 内存大小,还会做重新分配的内存空间,并将内容复制到新的地址。如果数量大的话,重新分配内存和拷贝内存会消耗大量时间。所以不适合大型字符串,也不适合存储量多的元素。
Sorted sets
使用场景:
- 排行榜;
- 基于滑动窗口的 rate limiter;
实现排行榜:
ZADD leaderboard:455 100 user:1
ZADD leaderboard:455 75 user:2
ZADD leaderboard:455 70 user:3
#获取排名前三的
ZRANGE leaderboard:455 0 2 REV WITHSCORES
实现 rate limiter 的方法:
- 可以参考这里, 实现参考:https://www.npmjs.com/package/rolling-rate-limiter。
- Rate Limiting using Redis Lists and Sorted Sets
推荐方法二,因为使用 Lua 脚本更简单,而且能够保证并发线程安全。
const redis = require("redis");
const redisClient = redis.createClient();
// 我们假设 1 分钟最多允许访问 5 次, 将 1 分钟之前的都删除掉。
const lua = `redis.call('ZREMRANGEBYSCORE', KEYS[1], 0, ARGV[1] - 60 * 1000)
// 假设一分钟只允许访问 products 5次
if tonumber(redis.call('ZCARD', KEYS[1])) < 5
then
redis.call('ZADD', KEYS[1], ARGV[1], ARGV[1])
return 'pass'
else
return 'exceeded limit'
end`;
redisClient.eval(lua, 1, 'products', Date.now(), function(err, replies) {
// replies will hold the data returned by Lua.
});
底层数据结构:
在 redis 中当元素个数不超过 128,且最大元素不超过 64 字节,使用 ziplist,当然是可配置的,见下面的配置。如果不满足以下配置要求,则采用 zskiplist。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
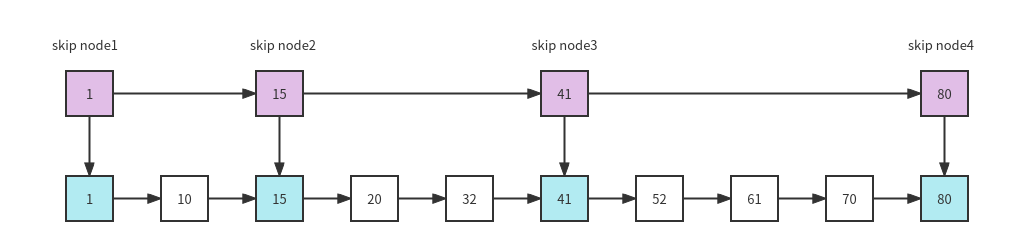
注:zskiplist 可以认为是 skiplist + hashtable 的合体。hashtable 保证搜索的高效,skiplist 可以认为是链表的升级版,它会存储若个跳板,让你一下子跳跃多个元素,这也是 skiplist 的优点,而传统的链表插入和删除元素效率相对较低。给大家一个 skiplist 的示意图:
温馨提示:反馈需要登录


